Anthropic ha portato in General Availability la context window da 1 milione di token per Claude Opus 4.6 e Sonnet 4.6. Non è più beta, non servono header speciali, e soprattutto non c’è nessun sovrapprezzo per il contesto lungo.
Una richiesta da 900.000 token costa esattamente come una da 9.000 - stesso prezzo per token, stessi rate limit, nessun moltiplicatore nascosto.
Cosa sono 1 milione di token in pratica
1 milione di token corrisponde indicativamente a diverse centinaia di migliaia di parole. Per dare un riferimento concreto:
- Un intero codebase aziendale caricato in una singola conversazione - niente più chunking o RAG per progetti di dimensioni medie
- Migliaia di pagine di contratti analizzate mantenendo il contesto completo tra clausole e documenti correlati
- Sessioni di agenti AI complete con tool calls, osservazioni e ragionamento intermedio senza dover svuotare la memoria
- Fino a 600 immagini o pagine PDF in una singola richiesta - 6 volte il limite precedente di 100
Il punto chiave: niente più workaround ingegneristici. Niente summarization lossy, niente context clearing, niente chunking manuale. Carichi tutto, Claude lavora su tutto.
Benchmark: Claude Opus 4.6 vs GPT-5.4 vs Gemini a 1M token
Il confronto più interessante è su MRCR v2 (Multi-needle Retrieval over long Context, 8-needle) - il benchmark che misura quanto bene un modello recupera informazioni sparse in contesti molto lunghi. È il test più rilevante per capire se un modello è effettivamente utilizzabile con finestre di contesto larghe.
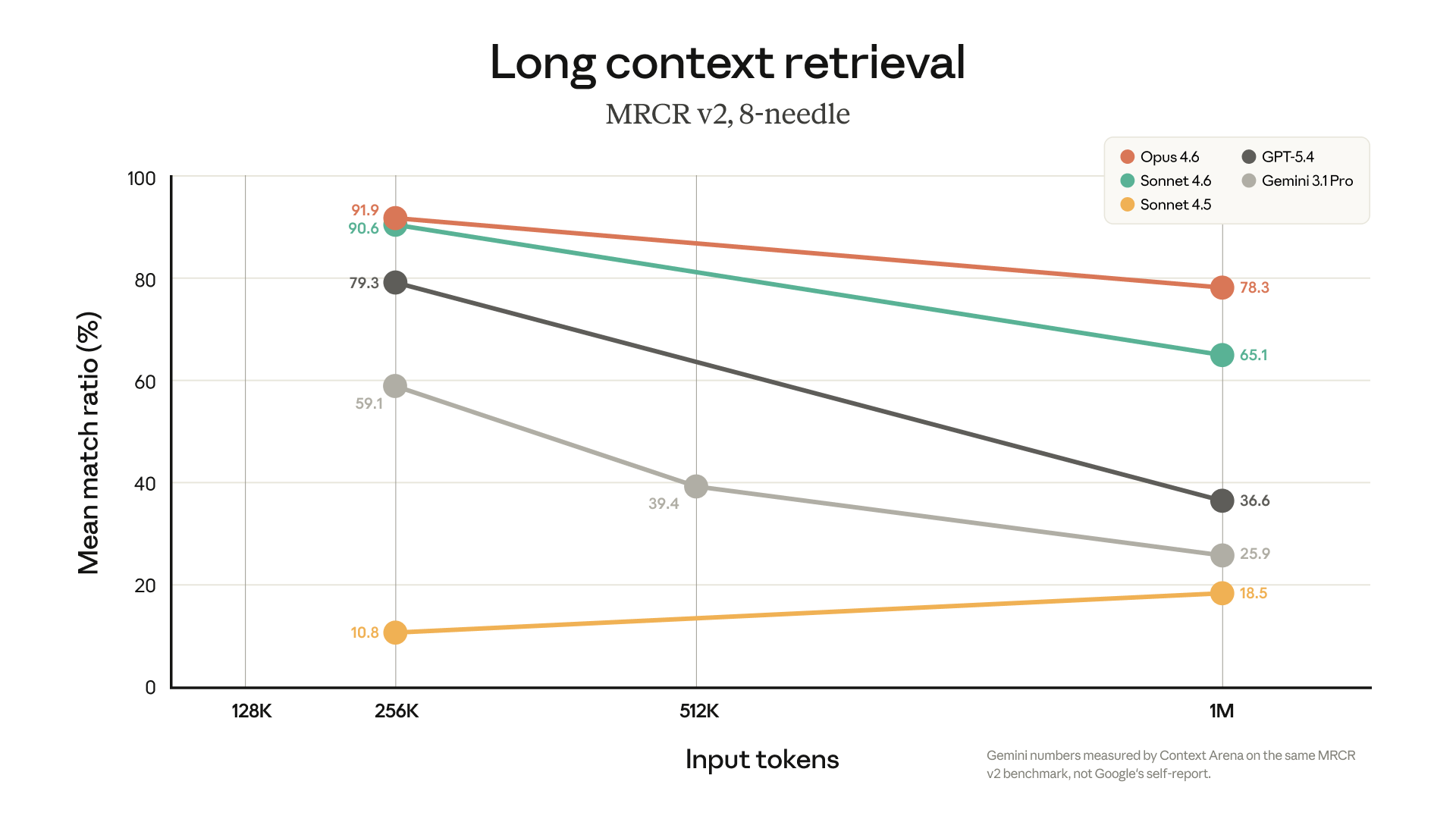
Accuratezza nel retrieval (MRCR v2, 8-needle) al crescere del contesto: Opus 4.6 mantiene il 78.3% a 1M token, mentre GPT-5.4 e Gemini degradano significativamente. Fonte: blog ufficiale Anthropic.
MRCR v2 - Accuratezza retrieval a 1 milione di token
I numeri sono netti. Opus 4.6 al 78.3% - più del doppio di GPT-5.4 (36.6%) e tre volte Gemini 3.1 Pro (25.9%). Non è una differenza marginale. (Nota: i dati di Gemini sono misurati da Context Arena sullo stesso benchmark MRCR v2, non auto-dichiarati da Google.)
A 256K token la situazione è più ravvicinata: Opus al 91.9%, Sonnet al 90.6%, GPT-5.4 al 79.3%, Gemini 3.1 Pro al 59.1%. Ma è proprio quando il contesto si allarga che la differenza diventa abissale. E il contesto largo è esattamente lo scenario delle applicazioni aziendali reali - documenti completi, codebase interi, audit di processo.
Prezzi Claude 1M token: nessun sovrapprezzo long context
Questo è il dettaglio che cambia i conti per chi costruisce applicazioni AI:
Pricing API - marzo 2026
Claude Opus 4.6
$5 / $25
per milione di token (input / output)
Nessun moltiplicatore long context
Claude Sonnet 4.6
$3 / $15
per milione di token (input / output)
Nessun moltiplicatore long context
Per essere chiari: non esiste un pricing tier separato per le richieste lunghe. Una chiamata API da 1 milione di token di input con Opus 4.6 costa $5. Punto. Questo rende economicamente sostenibile usare il contesto lungo per casi d’uso aziendali come l’analisi documentale, la revisione di codebase, e gli agenti AI complessi.
Dove è disponibile: API, Claude Code e cloud
La context window da 1 milione di token è disponibile su tutte le piattaforme principali:
- API Anthropic diretta - nessun header beta richiesto. Le richieste oltre 200K token funzionano automaticamente
- Claude.ai - per utenti Max, Team ed Enterprise
- Claude Code - meno compattazioni, più conversazione mantenuta intatta durante le sessioni di sviluppo
- Microsoft Azure Foundry - integrazione nativa per chi è nell’ecosistema Microsoft
- Google Cloud Vertex AI - per chi usa l’infrastruttura Google Cloud
Per gli sviluppatori: se usavate il vecchio header beta per il long context, viene semplicemente ignorato. Zero modifiche al codice.
Cosa cambia per Claude Code e gli sviluppatori
Per chi usa Claude Code quotidianamente - ed è uno strumento che usiamo anche noi in Martes AI - l’impatto è diretto. Le sessioni di sviluppo con Opus 4.6 ora hanno accesso all’intera finestra da 1M token, il che significa:
- Meno compattazioni - la conversazione rimane intatta più a lungo, senza che Claude perda il contesto di quello che avete fatto insieme
- Codebase interi in memoria - per progetti medio-grandi, Claude può tenere tutto il codice nel contesto senza dover cercare file ogni volta
- Trace di agenti complete - per chi costruisce sistemi AI multi-agente, l’intera catena di ragionamento, tool calls e osservazioni resta disponibile
Perché il contesto lungo conta per le aziende
Il limite di contesto è sempre stato il collo di bottiglia pratico nell’uso dell’AI per lavoro reale. Quando lavori su documentazione legale, su audit di processo, su analisi di documenti aziendali - il contesto non basta mai.
Fino a ieri, la soluzione era ingegneristica: RAG (Retrieval Augmented Generation), chunking, summarization, context management. Funziona, ma aggiunge complessità architetturale e perde informazione. Con 1 milione di token nativi, molti di questi workaround diventano superflui per dataset di dimensioni medio-grandi.
Questo non significa che RAG sia morto - per dataset enormi (milioni di documenti) serve ancora un layer di retrieval. Ma per il caso d’uso tipico aziendale - analizzare qualche centinaio di pagine, revisionare un codebase, mantenere il contesto di un progetto - 1 milione di token è sufficiente senza architetture aggiuntive.